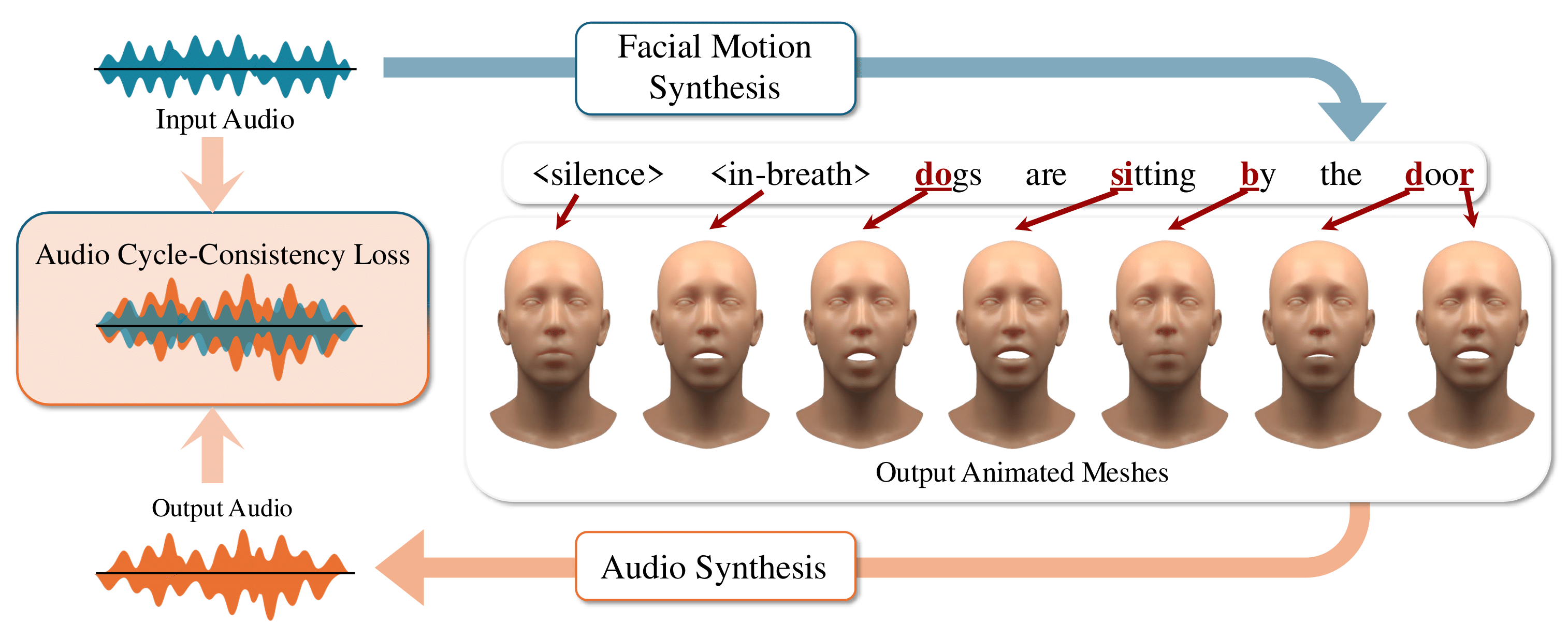
Mesh-to-Speech
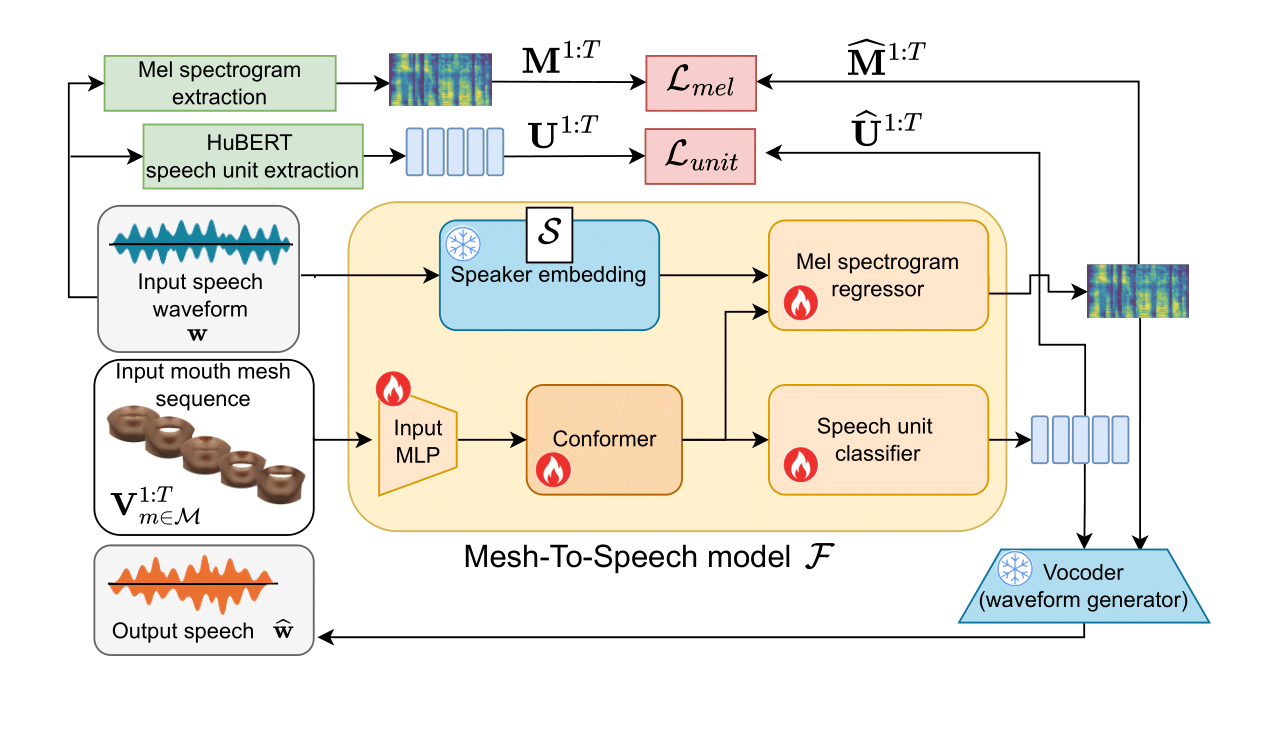
Using THUNDER's Mesh-to-Speech model, we can estimate spoken audio from a 3D animation of a face.
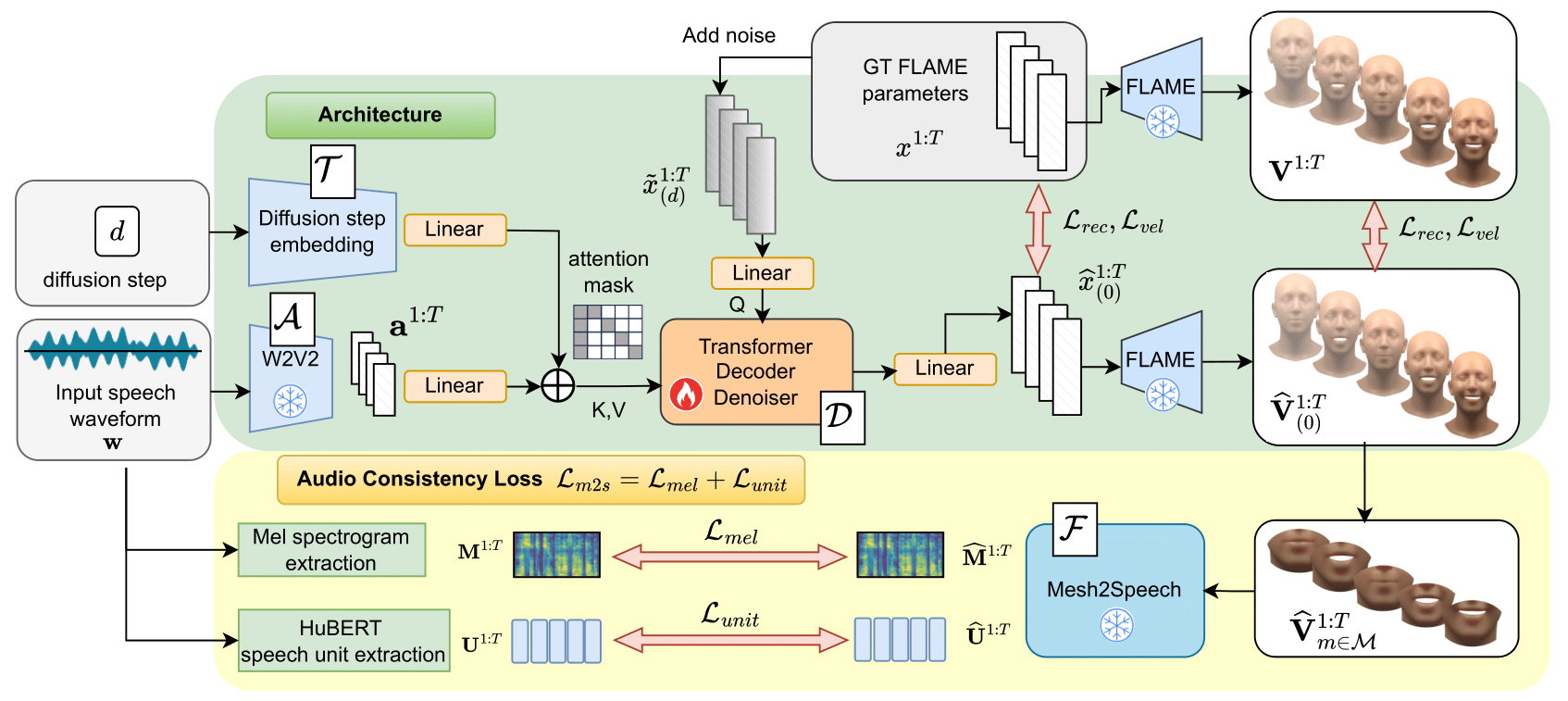
Architecture
The architecture of mesh-to-speech is based on the work of Choi et al., a known silent-video-to-speech model.
The architecture consists of an input feature encoder, a conformer sequence encoder and two prediction heads, a speech unit classifier, and a mel spectrogram regressor.
These two outputs contain enough information that a pretrained off-the-shelf vocoder from Choi et al. can turn them into output audio.
Since the input is not a video, but a 3D animation, we replace the original lip video ResNet encoder that Choi et al. use with an MLP that takes 3D lip vertex coordinates as the input.
Results
We run video-to-speech and mesh-to-speech models on the test subjects of the RAVDESS, GRID, and TCD-TIMIT datasets.
Please note that the test subjects (and their recordings) were not seen in training.
First column is the video with original audio (Ground Truth),
second column is the same video but the audio was produced by a silent-video-to-speech method of Choi et al. (the original released model),
third column's audio is produced by Choi et al. finetuned on our dataset.
The final column contains video of the pseudo-GT reconstruction of the video,
the audio recording is generated by our mesh-to-speech model from the depicted facial animation.
Results on RAVDESS
RAVDESS is a low-vocabulary dataset of emotional speech and song recordings.
Both video-to-speech and mesh-to-speech models perform well on this dataset, likely thanks to the limited vocabulary.
Ground Truth
Choi et al. (original)
Choi et al. (finetuned)
Mesh-to-Speech (ours)
Results on GRID
GRID is a much larger scale dataset with many more subjects and richer vocabulary than RAVDESS,
but the sentences present in the data are relatively artificial.
Again, both video-to-speech and mesh-to-speech models perform well on this dataset.
Ground Truth
Choi et al. (original)
Choi et al. (finetuned)
Mesh-to-Speech (ours)
Results on TCD-TIMIT
TCD-TIMIT is a dataset of much richer vocabulary and more natural sentences than RAVDESS and GRID and presents a greater challenge for both video-to-speech and mesh-to-speech models.
A finetuned video-to-speech model performs better than our mesh-to-speech model, but this is expected since our animations do not contain the teeth or the tongue,
making the task inherently more ambiguous and difficult.
Despite that, mesh-to-speech produces plausible sounds given the input animation's lip movements
Ground Truth
Choi et al. (original)
Choi et al. (finetuned)
Mesh-to-Speech (ours)
Ablation of input spaces
Here we ablate different possibilities of input spaces for our mesh-to-speech model.
We experiment with all face vertices (Face2Speech), FLAME expression vector (Exp2Speech) and mouth vertices (Mouth2Speech).
While all models are applicable for talking head avatar supervision, we opt for Mouth2Speech. See the paper for more details.
Ground Truth
Face2Speech
Exp2Speech
Mouth2Speech (final)